
오늘 목표
- 데이터 프레임 정리 (필요없는 열과 행 삭제, 거래량 천만주 이상 기준 종목 정리)
- 코드 실행시 일자별로 excel 파일 정리되도록
- 해당 종목 - 종목 코드 연결 - 종목 관련 기본 정보 크롤링까지 연결
오늘은 기존에 만들었던 코드에서 함수를 좀 가져다가 어제까지 만든 데이터 프레임과 각 종목의 기본 정보를 합치고 이걸 엑셀파일에 저장하는 것까지 완료했습니다. 세 시간 정도 걸린 것 같네요. 지난 기억을 더듬어가며 만드니 쉽지 않습니다.
데이터 프레임을 먼저 정리해야 하는데 상한가 종목을 가져온 데이터 프레임에 필요없는 열이 있었습니다. 아래 그림에서 Unnamed 라고 되어 있는 열들은 모두 제거를 해야 합니다. 이를 위해서 슬라이싱을 활용합니다.

df_upper1 = df_upper[1].iloc[:,:12].loc[df_upper[1]['N'].notnull()]df_upper2 = df_upper[2].iloc[:,:12].loc[df_upper[2]['N'].notnull()]
세 개의 데이터 프레임이 df_upper라는 변수 안에 리스트 형태로 들어있고 두 번째(df_upper[1])가 코스피, 세 번째(df_upper[2])가 코스닥의 상한가 종목이었습니다.
각각에 대해서 .iloc[:, :12] 메쏘드로 슬라이싱을 해 줍니다. DataFrame.iloc[행 범위, 열 범위]의 형태로 슬라이싱이 가능합니다.
그리고 데이터가 비어있는 쓸데없는 행을 제거하기 위해 .loc[df_upper[2]['N'].notnull()] 메쏘드로 'N'열에 값이 없는 행을 제거합니다.DataFrame.loc[DataFrame[열 이름].notnull()]은 해당 열에 데이터가 비어있지 않은 행의 데이터만 선택하라는 뜻입니다.
이렇게 정리를 한 후에 필요없어진 'N'열을 코스닥과 코스피를 구분하기 위해 각각 df_upper1['N'] = '코스피', df_upper2['N'] = '코스닥'와 같이 열의 데이터를 바꾸고 아래와 같은 코드로 열 이름을 '시장구분'으로 바꿔줍니다.
df_quant.rename(columns = {'N' : '시장구분'}, inplace = True)
이제 코스피와 코스닥 종목을 합쳐줍니다. Pandas.concat([DataFrame1, DataFrame2, ...])명령을 활용해 두 개 데이터 프레임을 합치면 아래와 같이 비교적 깔끔하게 정리가 됩니다.

이와 동일한 방식으로 천만 주 이상 거래 종목도 정리할 수 있는데 다른 점은 전체 리스트가 아니라 거래량이 천만이 넘는 주식을 한 번 더 슬라이싱하는 점입니다. 이는 DataFrame[DateFrame['열이름'] 조건식] 형태로 구현할 수 있습니다. 우리가 필요로 하는 건 거래량 상위 종목 중에서 거래량이 천만이 넘는 종목만 걸러내면 됩니다.
df_quant1 = df_quant1[1].loc[df_quant1[1]['거래량']>10000000].iloc[:,:12]df_quant2 = df_quant2[1].loc[df_quant2[1]['거래량']>10000000].iloc[:,:12]
이번에도 'N'열에 데이터 결손이 없는 종목에 열방향으로 의미없는 열을 잘라냈고 .loc[df_quant1[1]['거래량']>10000000] 메쏘드로 천만이 넘는 종목만 골라낼 수 있었습니다. 역시 'N'열을 활용해서 코스닥, 코스피 시장을 구분하고 두 개 데이터 프레임을 합치면 아래와 같이 거래량 천만주 이상 종목이 정리가 됩니다.
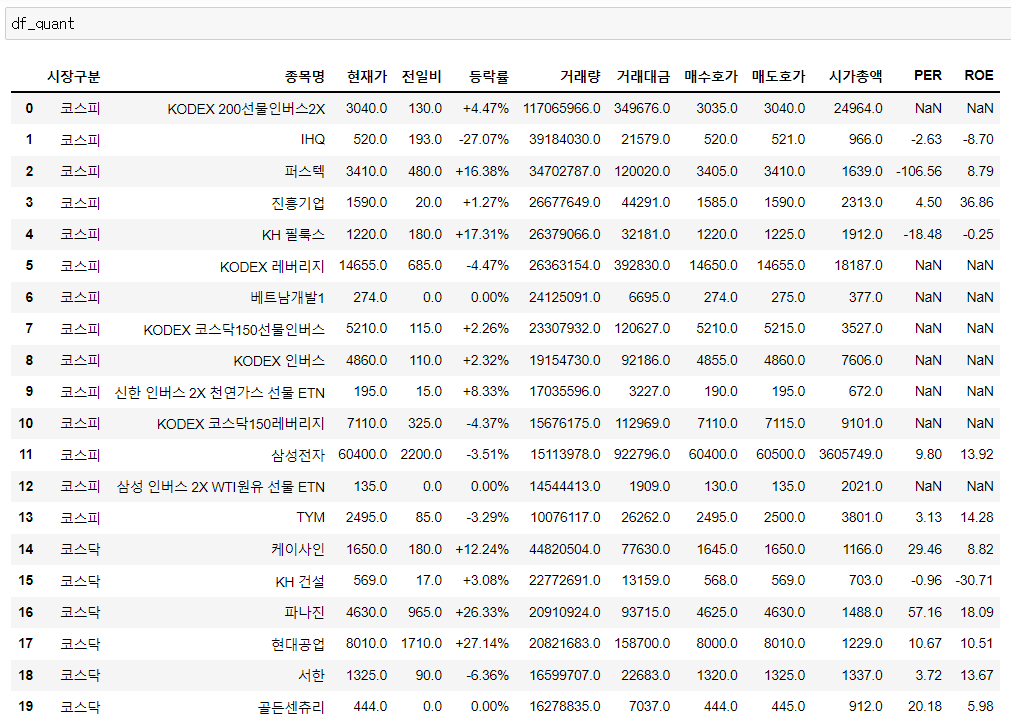
여기서부터 이전에 만들어 놓은 함수를 좀 활용했는데 두 가지입니다.
먼저 웹 크롤링하는 함수로 기업공시채널 KIND에서 상장 기업의 전체 List와 기본 정보를 가져오는 간단한 함수입니다.
def company_list_update():
url = 'http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13&marketType=%s'
res = requests.get(url)
stock_list_df = pd.read_html(url, header=0)[0]
return stock_list_df함수를 실행해서 반환되는 결과 데이터 프레임은 아래와 같습니다.
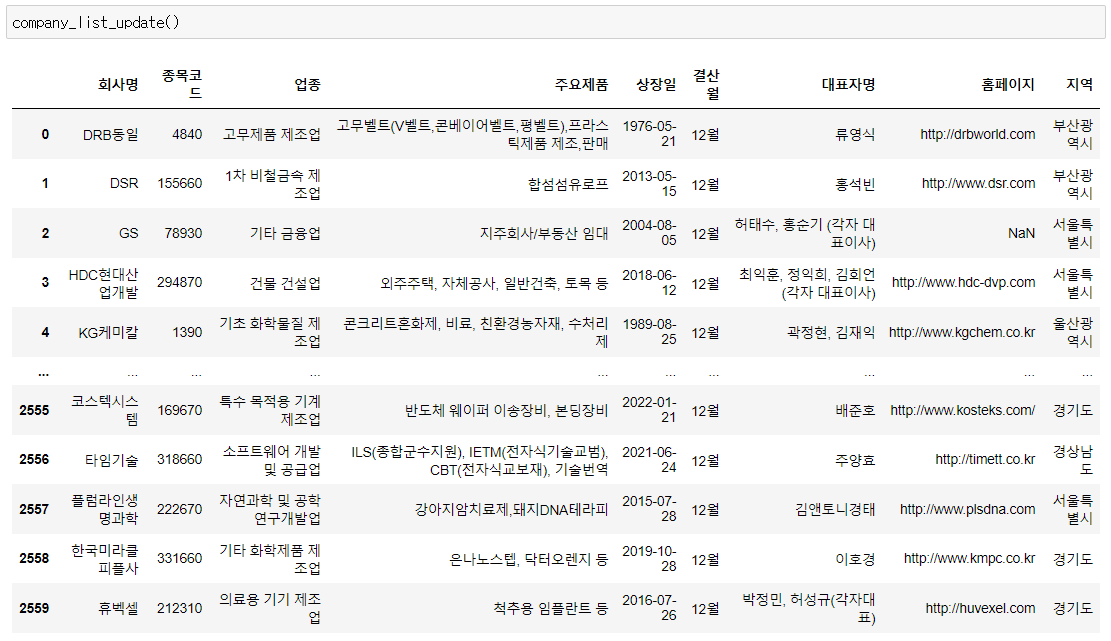
이 함수에 상장 종목의 기본 정보들이 나와 있으니 이 정보들과 앞의 상한가, 천만주 이상 거래 종목을 연결할 겁니다. 상한가 종목과 천만주 이상 거래 종목의 종목명과 상장 기업 정보의 회사명을 매칭해서 두 개 데이터 프레임을 합치는 겁니다. 이 과정에서 두 개 데이터 프레임의 인덱스와 순서가 일치해야하기 때문에 reset_index(drop=True, inplace=True)를 붙여줍니다. 데이터 프레임 뒤에 이 코드를 붙이면 인덱스가 지금의 데이터 프레임 기준을 순서대로 0,1,2,3.... 이렇게 다시 설정됩니다. drop=Ture를 인수로 넣어주지 않으면 기존의 인덱스가 살아서 한 개 열이 더 생기는데 큰 의미가 없기 때문에 없애는게 낫겠습니다. inplace=True를 인수로 넣어주면 기존 데이터프레임에 덮어씌워집니다. inplace를 쓰지 않으면 출력은 변경되지만 기존 데이터 프레임은 그대로 남아있기 때문에 주의해야 합니다.
df_list = pd.DataFrame()
for stock_name in df_upper['종목명']:
if stock_name.endswith('우'):
stock_name = stock_name[:-1]
df_list = pd.concat([df_list,stock_list[stock_list['회사명'] == stock_name]])
df_list.reset_index(drop = True, inplace = True)그리고 우선주의 경우는 상장기업 리스트에 안나오기 때문에 '우'라는 글자를 떼어줘야 합니다.
String.endswith(substing)은 해당 string이 substring으로 끝나는지를 Boolean(참/거짓)으로 반환하는 메쏘드입니다. '우'로 끝나는 종목명에 대해서 마지막 글자를 슬라이싱했습니다.
그리고 다시 concat함수를 이용해서 해당하는 종목들의 종목정보들을 쌓고 마지막에 다시 reset_index로 인덱싱을 초기화 합니다. 그리고 이렇게 생긴 df_list라는 데이터 프레임과 상한가 종목의 리스트인 df_upper를 다시 합쳐줍니다.
df_upper = pd.concat([df_upper, df_list], axis=1)
여기서 인수로 들어간 axis = 1은 가로방향으로 합치라는 뜻입니다. 인덱싱을 맞춰놨기 때문에 잘 합쳐집니다. 이렇게까지 합쳐진 최종 데이터 프레임은 아래와 같습니다. 글자가 많아서 지저분해 보이지만 엑셀로 보낼꺼니까 괜찮습니다.
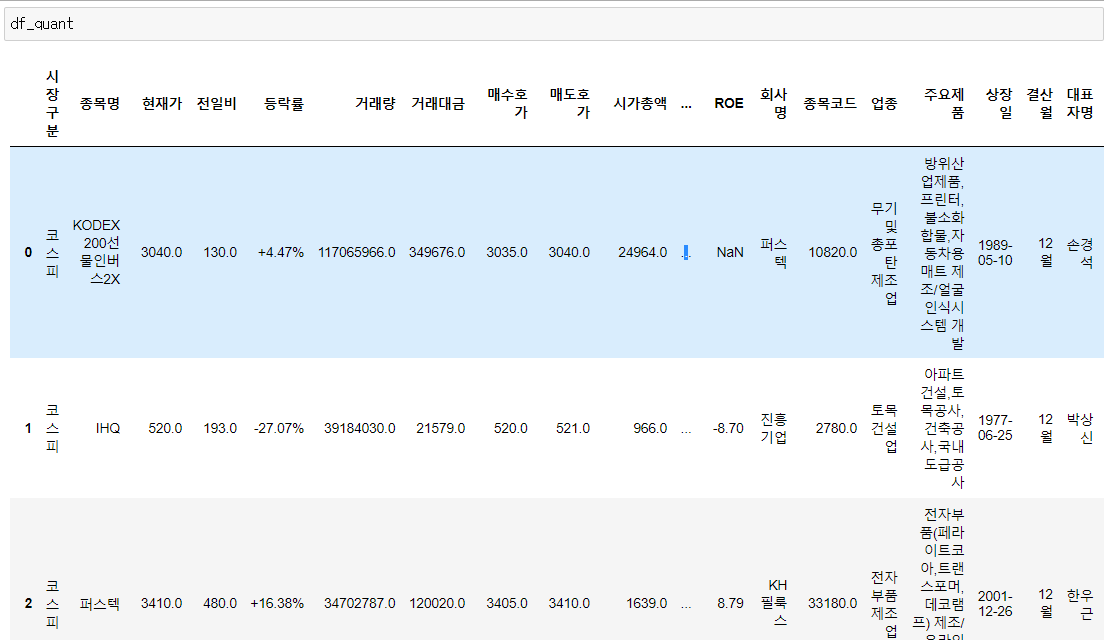
이제 마지막 단계는 데이터 프레임을 엑셀 파일로 넣어주는건데, 이번에도 이전에 만들어놨던 함수입니다. openpyxl모듈을 필요로 하기 때문에 설치 후 사용해야 합니다.
저는 일자별로 하나의 파일에 관리하기 위해서 파일명은 고정하고 생성 날짜로 시트 이름이 생성되게 했습니다. 만약 파일이 없는 상태에서 처음 실행하면 파일부터 생성됩니다. openpyxl 모듈에는 데이터 프레임을 열로 쪼개서 엑셀 워크시트에 넣어주는 메쏘드가 있습니다.
def df_to_xls(df, filename):
import openpyxl
from openpyxl.utils.dataframe import dataframe_to_rows
try :
wb = openpyxl.load_workbook(filename+'.xlsx')
except :
wb = openpyxl.Workbook()
today = str(dt.date.today().isoformat())
try :
ws = wb[today]
except :
wb.create_sheet(index = 0, title = today)
ws = wb[today]
for r in dataframe_to_rows(df, index = False, header = True):
ws.append(r)
wb.save(path+filename+'.xlsx')
pass이 함수는 인수로 데이터 프레임과 생성하고자 하는 파일명을 넣어주면 미리 지정한 경로의 폴더에 지정한 이름의 파일이 생성되거나 이미 생성된 파일에 해당 데이터 프레임을 생성날짜 이름의 시트에 추가해 줍니다. 이렇게 하면 폴더에 엑셀 파일이 생기고 그 안에 데이터가 들어가 있습니다.


전체 코드는 아래와 같습니다. 지저분하고 복잡하네요. 언제쯤 깔끔하게 코딩을 할 수 있을지 모르지만 일단 번거로운 일을 덜어줄 수 있는 코딩을 했다는 것에 만족합니다. 이제 내일부터 실전용으로 써봐야겠습니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime as dt
#엑셀 파일 저장할 경로 지정
path = "C:\\Users\\LG\\Desktop\\python output\\"
#데이터 프레임을 엑셀로 저장하는 함수
#파일명은 인수로 전달, sheet명은 생성 날짜, 파일이 없으면 새로 생성
def df_to_xls(df, filename):
import openpyxl
from openpyxl.utils.dataframe import dataframe_to_rows
try :
wb = openpyxl.load_workbook(filename+'.xlsx')
except :
wb = openpyxl.Workbook()
today = str(dt.date.today().isoformat())
try :
ws = wb[today]
except :
wb.create_sheet(index = 0, title = today)
ws = wb[today]
for r in dataframe_to_rows(df, index = False, header = True):
ws.append(r)
wb.save(path+filename+'.xlsx')
pass
#상장사 List 가져오는 함수
def company_list_update():
url = 'http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13&marketType=%s'
res = requests.get(url)
stock_list_df = pd.read_html(url, header=0)[0]
#code_list_arr = stock_list_df['종목코드']
#stock_list_df.to_excel(path+'company_list.xlsx')
return stock_list_df
stock_list = company_list_update()
#상한가 종목
url_upper = 'https://finance.naver.com/sise/sise_upper.naver'
res_upper = requests.get(url_upper)
soup_upper = BeautifulSoup(res_upper.content, 'html.parser', from_encoding='cp949') #한글이 깨져서 뒤에 from_encoding='cp949' 추가함
table_upper = soup_upper.find_all('table')
df_upper = pd.read_html(str(table_upper)) #str()을 안 붙이면 변수명을 html 언어로 인식
#12번째 인덱스 이후를 슬라이싱하고 N열이 결손인 데이터 제외
df_upper1 = df_upper[1].iloc[:,:12].loc[df_upper[1]['N'].notnull()]
df_upper2 = df_upper[2].iloc[:,:12].loc[df_upper[2]['N'].notnull()]
# 시장 구분
df_upper1['N'] = '코스피'
df_upper2['N'] = '코스닥'
#데이터프레임 합치기
df_upper = pd.concat([df_upper1, df_upper2]).reset_index(drop=True)
df_upper.rename(columns = {'N' : '시장구분'}, inplace = True)
#해당하는 종목의 정보를 합쳐서 데이터 프레임을 만듦
df_list = pd.DataFrame()
for stock_name in df_upper['종목명']:
if stock_name.endswith('우'):
stock_name = stock_name[:-1]
df_list = pd.concat([df_list,stock_list[stock_list['회사명'] == stock_name]])
df_list.reset_index(drop = True, inplace = True)
#원래 List랑 합침
df_upper = pd.concat([df_upper, df_list], axis=1)
#Excel 파일에 update
df_to_xls(df_upper, '상한가')
#거래량 상위 종목 (코스피)
url_quant1 = 'https://finance.naver.com/sise/sise_quant.naver?sosok=0'
res_quant1 = requests.get(url_quant1)
soup_quant1 = BeautifulSoup(res_quant1.content, 'html.parser', from_encoding='cp949')
table_quant1 = soup_quant1.find_all('table')
df_quant1 = pd.read_html(str(table_quant1))
#N열이 결손인 데이터 제외하고 거래량 천만주 이상만 슬라이싱, 의미없는 인덱스 삭제
df_quant1 = df_quant1[1].loc[df_quant1[1]['N'].notnull()].loc[df_quant1[1]['거래량']>10000000].iloc[:,:12]
#거래량 상위 종목 (코스닥)
url_quant2 = 'https://finance.naver.com/sise/sise_quant.naver?sosok=1'
res_quant2 = requests.get(url_quant2)
soup_quant2 = BeautifulSoup(res_quant2.content, 'html.parser', from_encoding='cp949')
table_quant2 = soup_quant2.find_all('table')
df_quant2 = pd.read_html(str(table_quant2))
#N열이 결손인 데이터 제외하고 거래량 천만주 이상만 슬라이싱, 의미없는 인덱스 삭제
df_quant2 = df_quant2[1].loc[df_quant2[1]['N'].notnull()].loc[df_quant2[1]['거래량']>10000000].iloc[:,:12]
# 시장 구분
df_quant1['N'] = '코스피'
df_quant2['N'] = '코스닥'
#데이터프레임 합치기
df_quant = pd.concat([df_quant1, df_quant2]).reset_index(drop = True)
df_quant.rename(columns = {'N' : '시장구분'}, inplace = True)
#해당하는 종목의 정보를 합쳐서 데이터 프레임을 만듦
df_list = pd.DataFrame()
for stock_name in df_quant['종목명']:
#우선주의 경우 뒤에 '우'자를 떼어내서 에러 방지
if stock_name.endswith('우'):
stock_name = stock_name[:-1]
df_list = pd.concat([df_list,stock_list[stock_list['회사명'] == stock_name]])
df_list.reset_index(drop = True, inplace = True)
#원래 List랑 합침
df_quant = pd.concat([df_quant, df_list], axis=1)
#Excel 파일에 update
df_to_xls(df_quant, '천만주 이상 거래')'coding' 카테고리의 다른 글
| 상한가 및 천만주 이상 주식 정리 코딩 1일차 (0) | 2022.12.04 |
|---|